This is the first of (hopefully) a series of posts about playing with mechinterp and Fourier components, inspired by and replicating Goodfire's paper Arithmetic in the Wild.
About the paper
The main idea of the paper is that, for Llama-3.1-8B, the model uses an internal circular representation based on Fourier components to handle both conventional number arithmetic and months, years, and 24-hour time; e.g., when answering "2 + 5 = " or "What month is 1 month after December?".
A good chunk of that was already known from, among others, Kantamneni et al. and Engels et al..
What the paper adds is a surprising multi-step behavior for modular addition across all tasks: taking months as an example, instead of directly doing base-12 modular arithmetic, the model first runs the addition as conventional base-10 addition in lower layers, "four + November = 15", using this common structure for all tasks, and then later converts this back to the month representation, "15 -> March".
About this post
In this post, I replicate both the coarse localization and the Fourier probes with PCA. There are many experiments left, hopefully for a future post; see the follow-up section at the end for details.
The model of choice was microsoft/Phi-mini-MoE-instruct; in the last section, I explain the rationale for that and some caveats.
The database and code were created from scratch, which caused some small discrepancies in methodology relative to the original article, but it's part of the fun.
My code is available in the mechinterp-arithmetic-months GitHub repo.
Prompts setup
The prompts follow a simple structure.
The base (original) prompt:
- prompt: Answer in one word. What month is 1 month after December?
- expected answer: January
- input: December
- offset: 1
A counterfactual prompt:
- prompt: Answer in one word. What month is 3 months after May?
- expected answer: August
- input: May
- offset: 3
The expected answers for the patched base prompt, if we patch it using activations from the counterfactual prompt:
- expected answer when patching at the input position: June
- expected answer when patching at the offset position: March
Before being fed to the model, the prompts go through the chat template, so they become:
<|user|>\nAnswer in one word. What month is 1 month after December?<|end|>\n<|assistant|>\n
Coarse localization
In Appendix C, they run a ``crude'' experiment of intervening and patching full activations on the residual stream:
- sweeping through layers
- for each task
- with patching happening at 3 token positions.
The metric is Interchange Intervention Accuracy (IIA): the proportion (across prompt instances) of cases where the intervention causes the desired behavior to happen:
$$ \mathrm{IIA} = \frac{1}{N} \sum_{i=1}^{N} \mathbf{1} \left[ \hat{y}_i^{\mathrm{int}} = y_i^{\star} \right], \qquad \hat{y}_i^{\mathrm{int}} = \arg\max_t p_{\mathrm{int}}(t \mid x_i). $$
Coarse localization: results
The results matched the original article quite well:
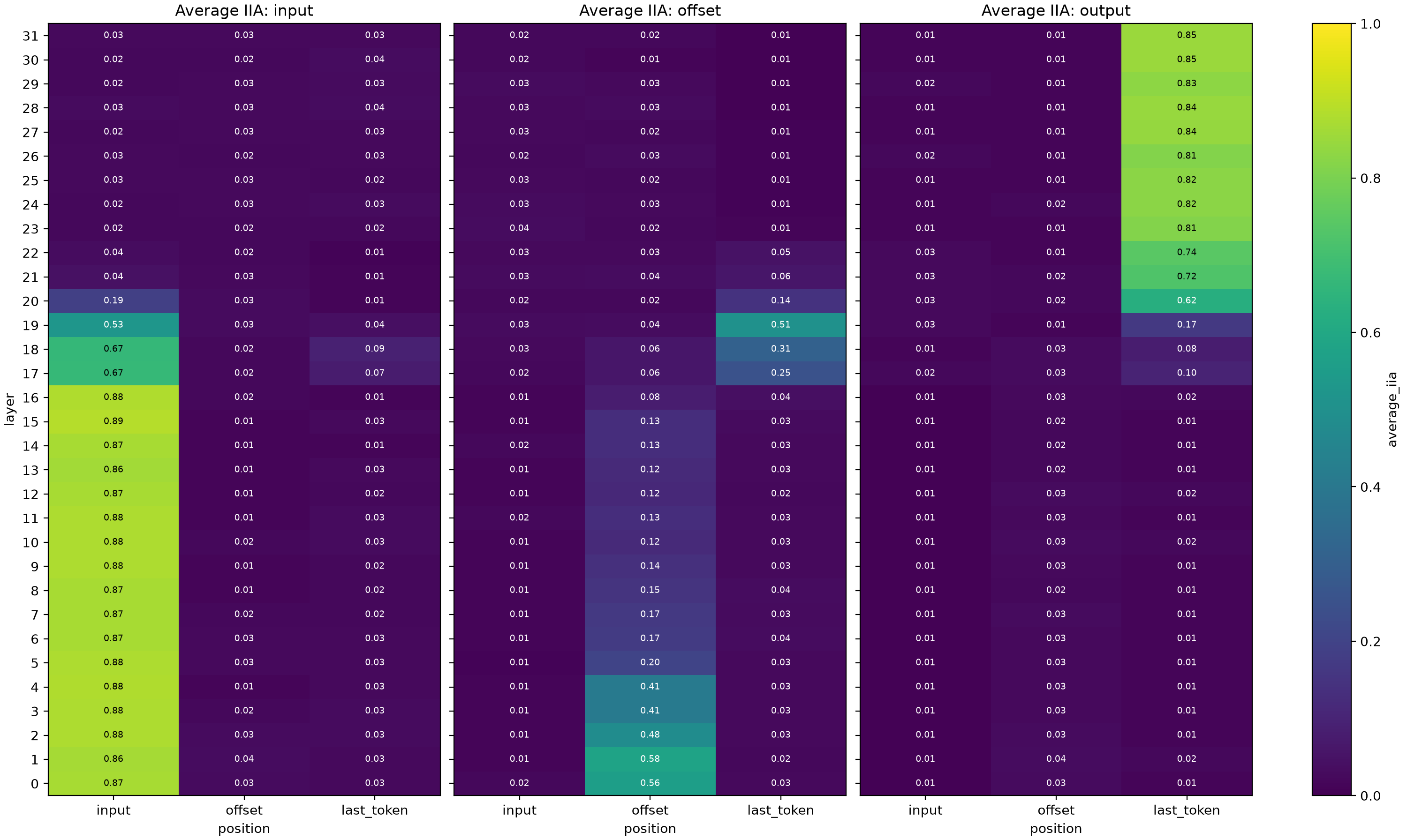
If we patch the activation at the input token position:
- We get a good IIA for the expected answer for "base prompt patched with input of counterfactual" for the early layers.
If we patch the activation at the offset token position:
- We get a good IIA for the expected answer for "base prompt patched with offset of counterfactual" for the early layers.
These two are expected: at early layers, the input information can be patched and affect the final result as if the base prompt had that input, but eventually, at higher layers, the input information might be transferred to the last token activations (e.g., to run some calculations in the MLP layers), so patching the input may no longer work. The same applies to the offset.
Now, if we patch the activation at the last token position:
-
We get a good IIA for the expected answer for the counterfactual prompt in the later layers. This is expected, given the previous observations: the information is eventually transferred to the last token activations (e.g., to run some calculations in the MLP layers).
-
In the middle layers, we get a good IIA for the expected answer for "base prompt patched with offset of counterfactual" for the early layers. This is evidence of the point where the offset information is being transferred to the activations of the last token position, but not the input yet (note that if both input and offset are transferred, then the expected answer is basically the same as the counterfactual prompt information).
-
In the middle layers, we get quite a weak IIA increase for the expected answer for "base prompt patched with input of counterfactual" for the early layers. This could either be the input being transferred to some extent but at a slower pace, or model errors caused by being in a blurry state.
An interesting difference from the results in Goodfire's paper is that the cutoff layer, where the information is transferred to the last token, seemed to be layer 18, but here layer 20 seems like the stronger contender.
Circular probes with PCA
Here the idea is to reduce the dimensionality of the activations using PCA and run circular probes (actually linear in parameters):
$$ \cos\left(\frac{2\pi m_i}{T}\right) = \beta_{0}^{(\cos)} + \beta_{1}^{(\cos)} z_{i1} + ... + \beta_{5}^{(\cos)} z_{i5} + \varepsilon_i^{(\cos)} $$
$$ \sin\left(\frac{2\pi m_i}{T}\right) = \beta_{0}^{(\sin)} + \beta_{1}^{(\sin)} z_{i1} + ... + \beta_{5}^{(\sin)} z_{i5} + \varepsilon_i^{(\sin)} $$
Note that $T=12$.
Circular probes with PCA: results
Again, the results matched the original article quite well:
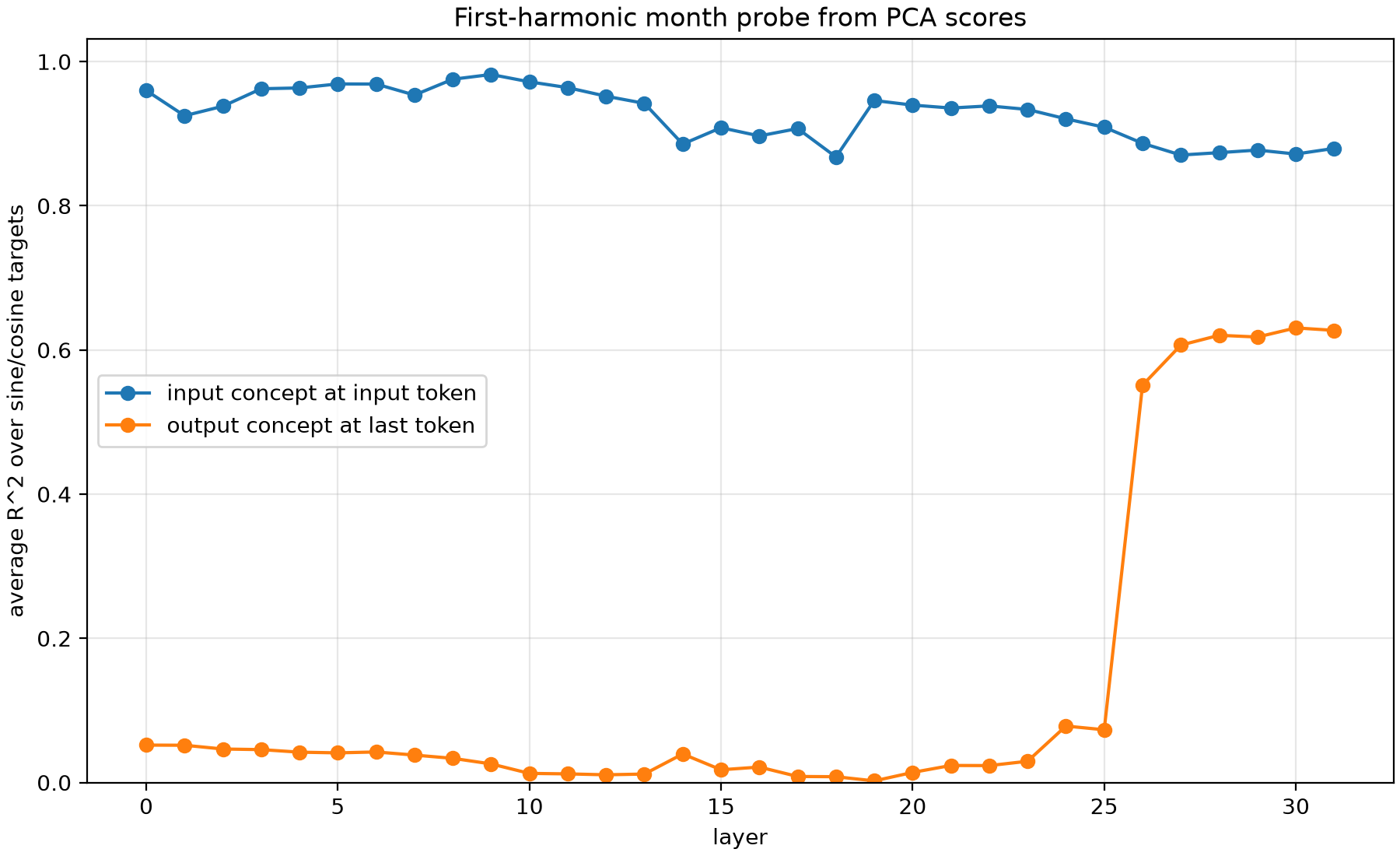
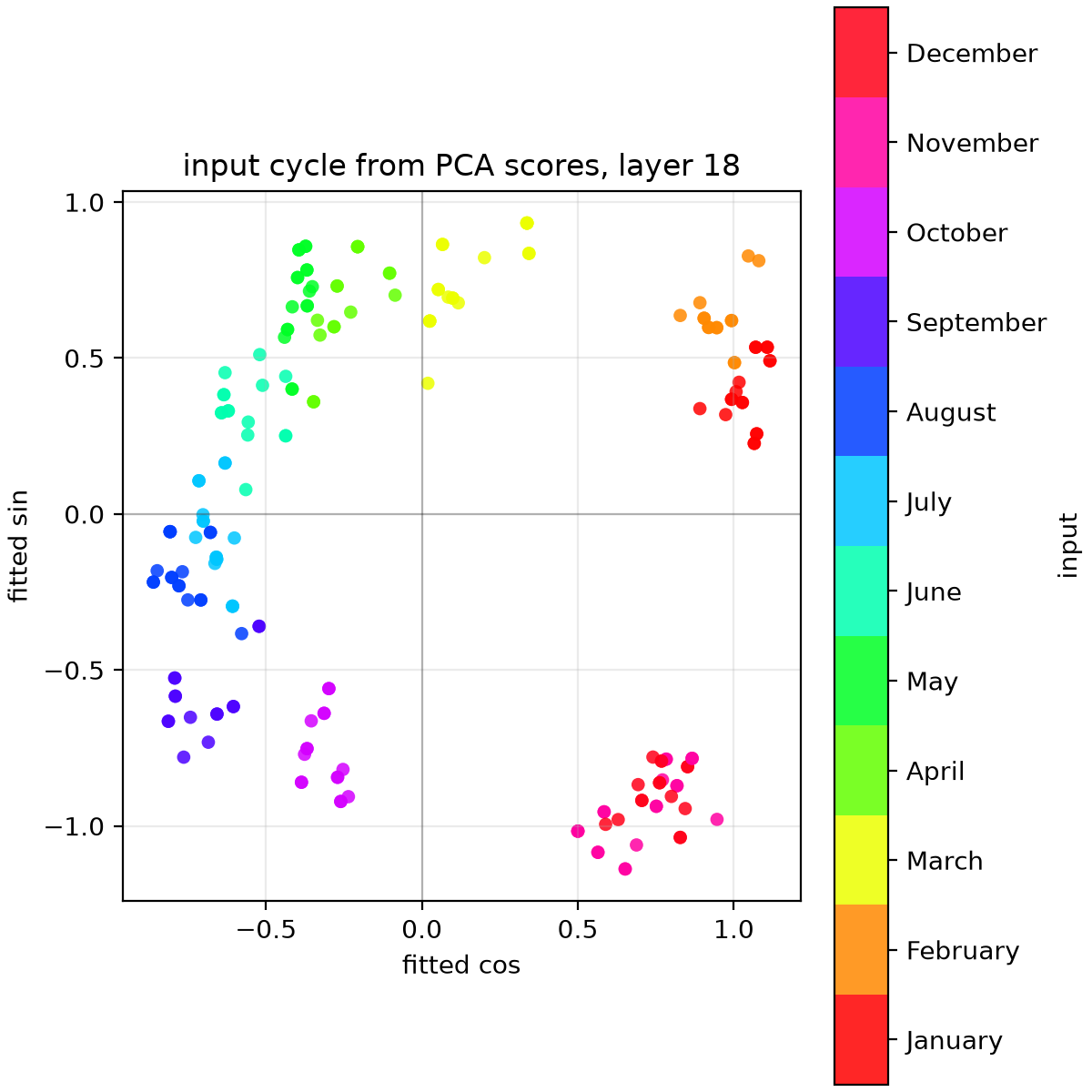
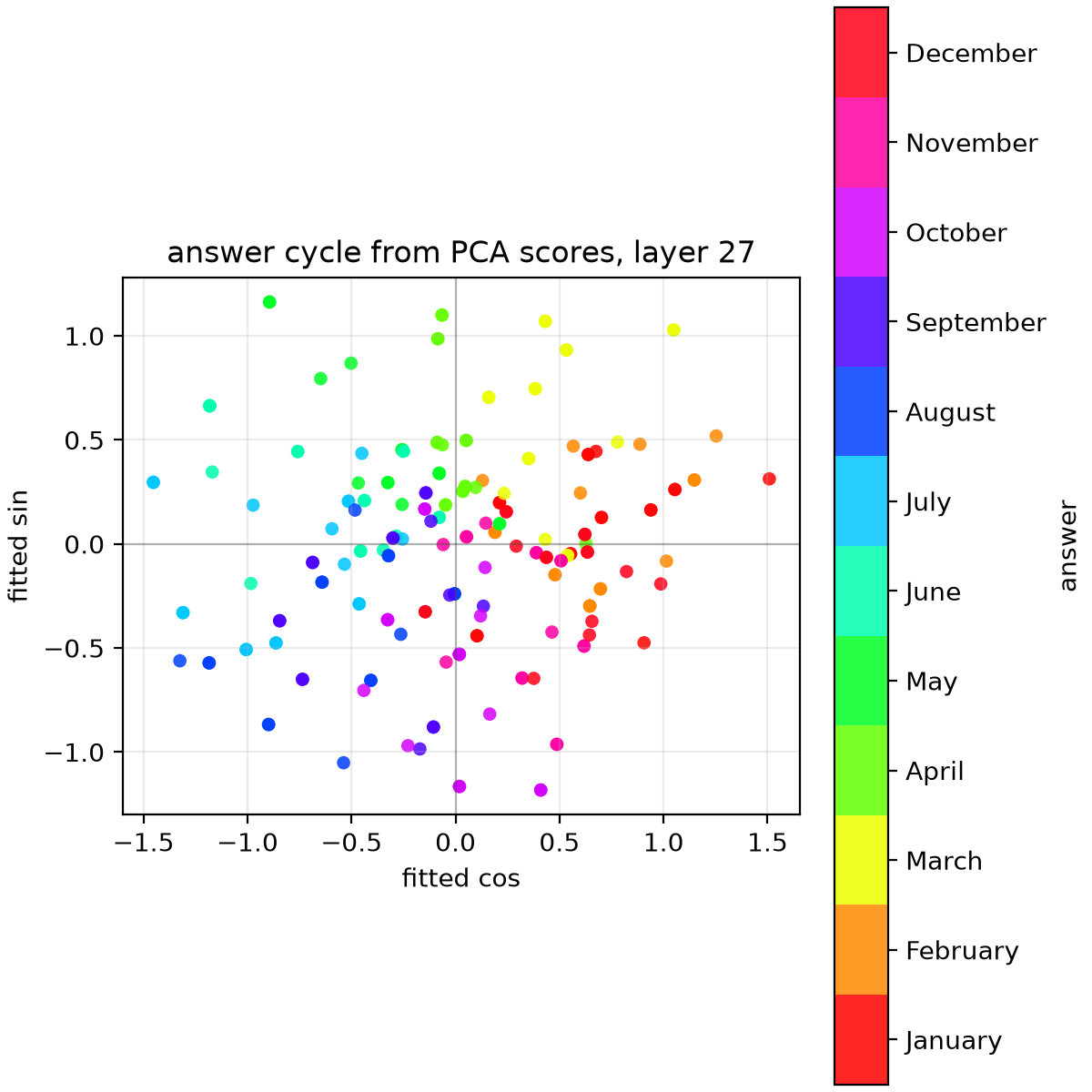
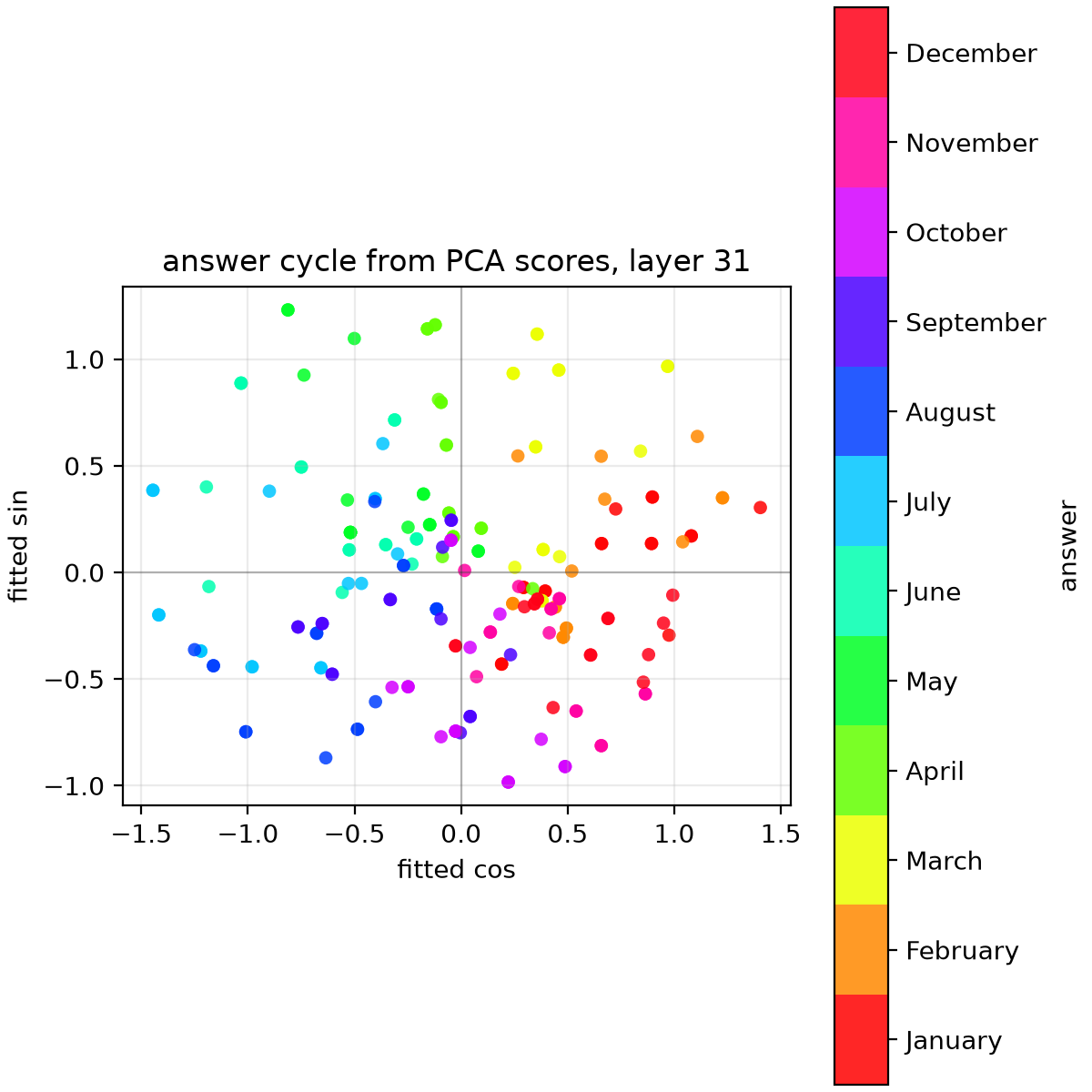
In a similar fashion, we can easily recover the first sine and cosine Fourier components with $T=12$ across basically all layers when looking at activations at the input token position.
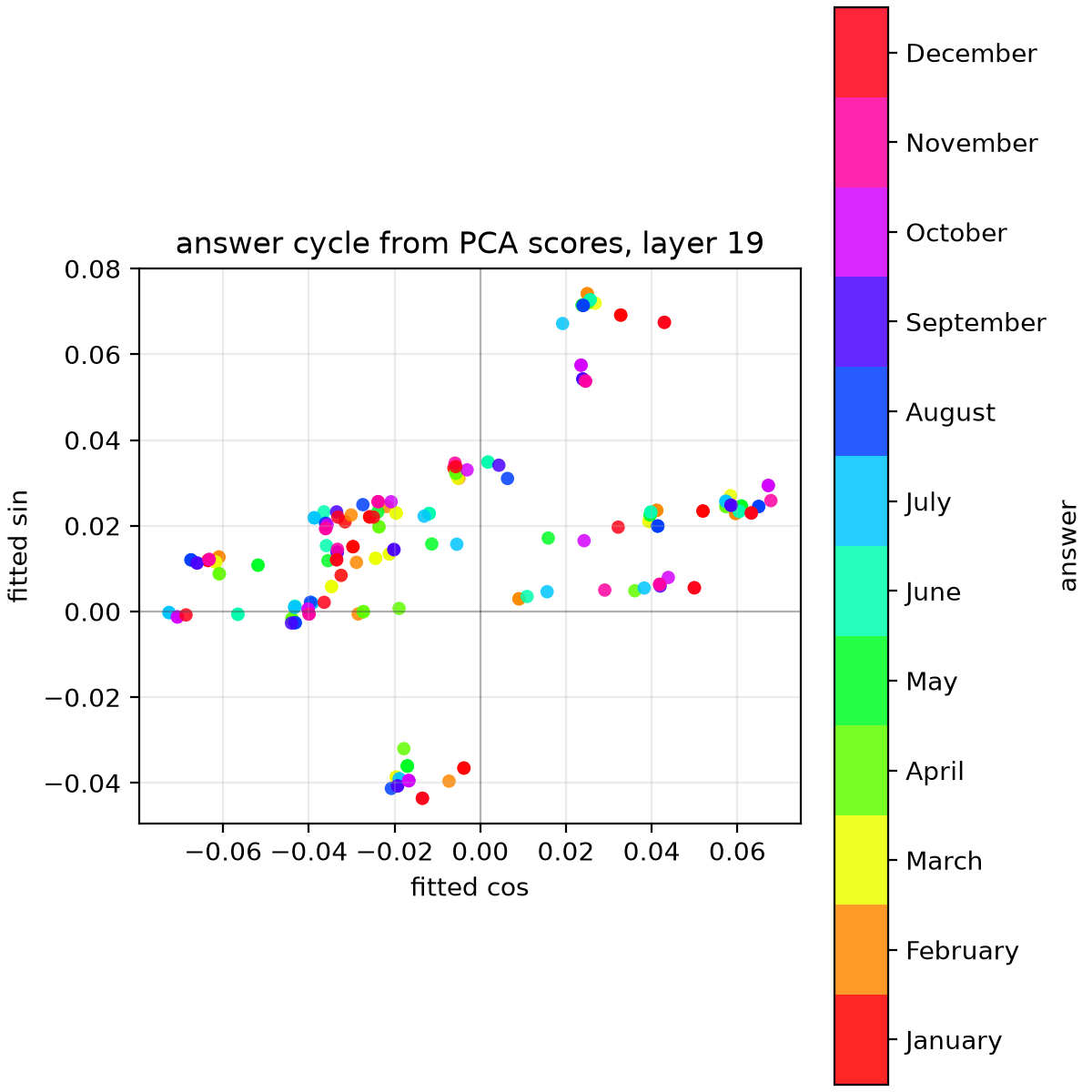
However, when looking at activations at the last token position, we can't recover them until after layer 25, even though the earlier experiment showed evidence of the information being reliably transferred to the last token position activations after layer 20.
This is in line with their conclusion that the information is processed as base-10 addition at this earlier point after the transfer and only later converted back to months using Fourier components of $T=12$.
Caveats when running
Here are some caveats I ran into while designing and running the experiments.
Model choice
The original meta-llama/Llama-3.1-8B is dense, so it is not efficient on my Strix Halo machine, and what fun would there be in just trying the same model?
Qwen/Qwen3-30B-A3B-Instruct-2507 was powerful but slow for fast experimenting. Moreover, to avoid blowing through the 128GB of memory I have, loading required some workarounds to incrementally move memory allocation from cpu to gpu (even though it's in the same memory pool, the allocations seemed to diverge).
LiquidAI/LFM2.5-8B-A1B seemed powerful but also had a mandatory chain-of-thought, which complicated things.
So, microsoft/Phi-mini-MoE-instruct seemed like a great match for my hardware.
Modify your pyproject
The released version of TransformerLens doesn't support Phi-mini-MoE-instruct or LiquidAI/LFM2.5-8B-A1B, but I submitted a patch that has recently been merged to make it work:
[project]
...
dependencies = [
...
"transformer-lens>=3.3.0",
]
[tool.uv.sources]
transformer-lens = {
git = "https://github.com/TransformerLensOrg/TransformerLens.git",
branch = "dev"
}Trusting remote code
This can be a little counterintuitive: by setting trust_remote_code=True, you may feel like you won't break anything, and will only potentially add some optional extras if they are necessary (it feels like this flag is just about security). But in reality, when Phi-MoE was launched, it was not supported directly by the transformers library, so they had to add some Python code in the repo. Now there is native support, and this code in the repo actually causes problems because it targets older versions of the transformers library. So, use trust_remote_code=False.
Using text instead of tokens
There are some footguns here; see the discussion in the issue that I raised.
Padding
In general, you should check whether your prompts are being tokenized into sequences of the same length, and if not, you might need to add padding and pass it around. Using text with TransformerLens might simplify things regarding padding (e.g., check model.generate(input) on TransformerLens when the input is tokens and when it's text), but it can run into the problems mentioned above.
Follow-ups
(Hopefully) I want to follow this post by applying this to the other tasks (days of the week, hours, and numbers), as well as applying distributed alignment search, cross-patching, steering with Fourier probes, and neuron identification, as was done in the original paper.